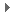[Youtube]p1b5aiTrGzY[/Youtube]
▲ 想看歷史人物、畫像人物動起來的可直接移動至 4:18 處。

要打造令人信服的 deepfakes 影片,神經網路模型往往需要經過大量數據訓練才能達成,但現在三星(Samsung)莫斯科 AI 研究中心的團隊已經開發出一種方法,只需要「少許」影像數據就能打造出可信度相當高的談話影片。但少許究竟是多少?根據團隊的描述,這個數字可以是 32 張或 8 張照片,又或者更少一些──1 張照片也行。
據了解,這款 AI 模型是使用卷積神經網路(CNNs)所打造,團隊先是使用 VoxCeleb 公開數據庫中超過 7,000 張名人圖像對演算法進行了訓練,讓 AI 關注於辨識人們臉部的「地標」特徵,像是眼睛、嘴巴形狀、鼻樑長度和形狀,它開始能以相似的做法應用在其他照片上,使照片活過來。
由於 AI 模型最少只需要 1 張照片便可以進行,這意味著歷史人物或肖像畫都能夠適用,在影片中,可以看到愛因斯坦、杜斯妥也夫斯基和夢露的著名肖像動起來,就好像他們在現代生活,被一旁友人拍下講話的畫面一樣。
當然,使用越多照片的效果明顯越好,只使用 1 張照片製作的 deepfakes 影片很容易就能從背景、臉部表情的不自然看出造假痕跡,只是隨著使用的對象生活年代越早,也越難從影片中看出虛假──畢竟許多人在攝影技術普及前早已離世,並沒有留下實際的談話影片讓我們能夠對照真偽。
要說這個 AI 模型最讓人驚豔的一點,應該還是讓畫像人物也能夠動起來的部分,以知名的「蒙娜麗莎」為例,過去即使前往羅浮宮美術館朝聖,頂多也只能感覺蒙娜麗莎像從任何角度都在看著你,可沒有辦法看到蒙娜麗莎對你眨眨眼,又或者像是在談起生活瑣事。 
▲ 在造假技術協助下,畫像中的人物就像被賦予了生命。
隨著 deepfakes 技術越來越進步,許多人都開始擔心相關技術被應用在惡意用途,讓未來即使看到影片、聽到聲音檔仍「眼見不能為憑」。儘管潛在疑慮仍然存在,但至少以目前來說,還未有任何 deepfakes 影片造成嚴重的混亂事件──當然,這是目前啦,未來會如何發展就不好說了。
|